
以前写的版本不能用了?

原接口不返回数据了…

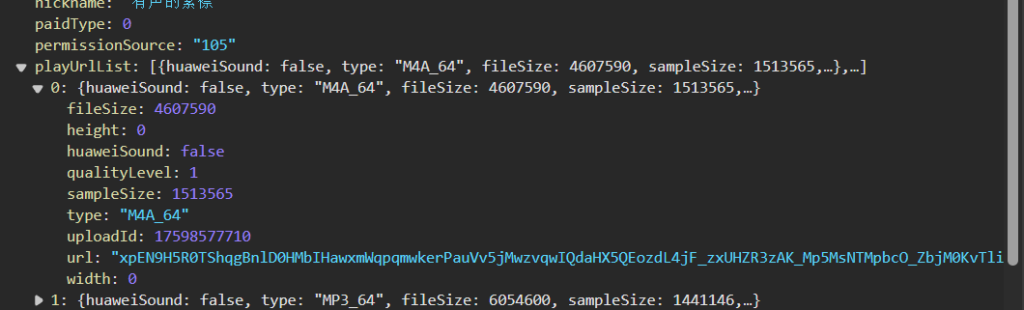
前后端通讯加密
1 hours later
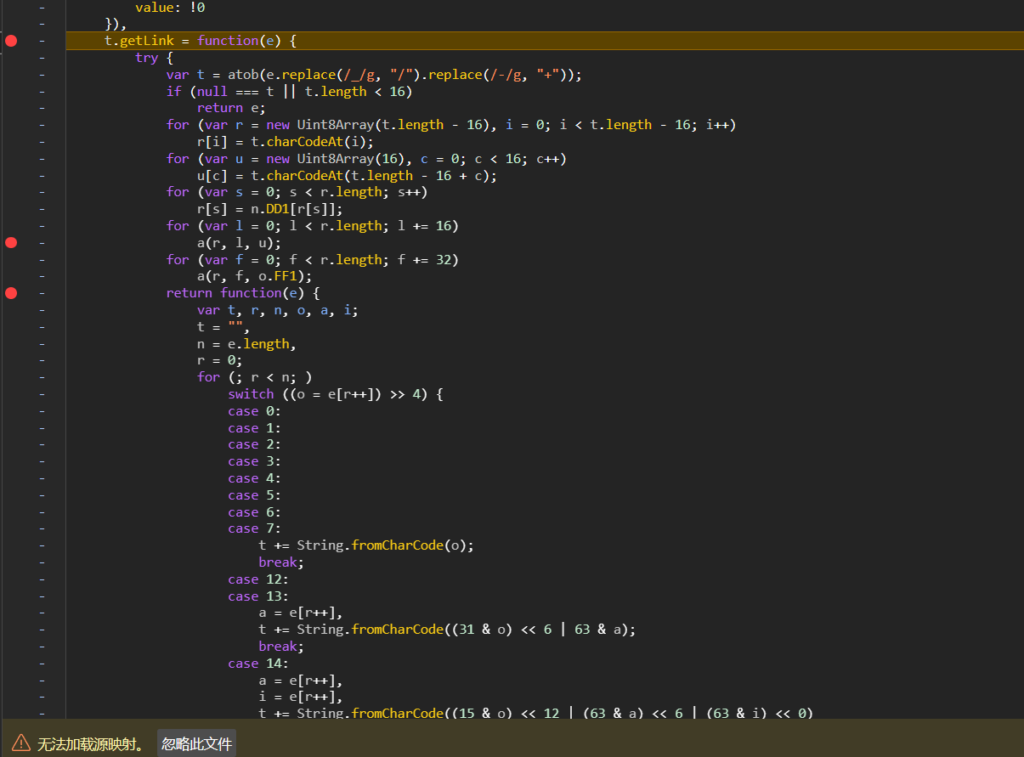
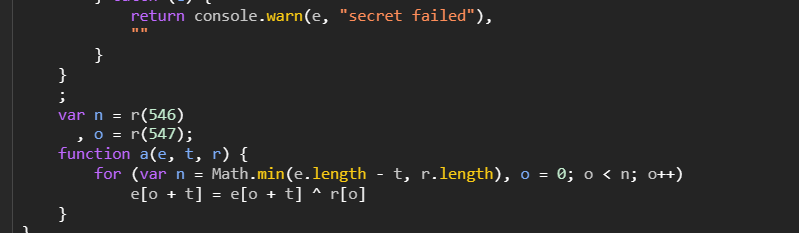
gpt改写,再改改,解密终版如下
DD1 = [183, 174, 108, 16, 131, 159, 250, 5, 239, 110, 193, 202, 153, 137, 251, 176, 119, 150, 47, 204, 97, 237, 1, 71, 177, 42, 88, 218, 166, 82, 87, 94, 14, 195, 69, 127, 215, 240, 225, 197, 238, 142, 123, 44, 219, 50, 190, 29, 181, 186, 169, 98, 139, 185, 152, 13, 141, 76, 6, 157, 200, 132, 182, 49, 20, 116, 136, 43, 155, 194, 101, 231, 162, 242, 151, 213, 53, 60, 26, 134, 211, 56, 28, 223, 107, 161, 199, 15, 229, 61, 96, 41, 66, 158, 254, 21, 165, 253, 103, 89, 3, 168, 40, 246, 81, 95, 58, 31, 172, 78, 99, 45, 148, 187, 222, 124, 55, 203, 235, 64, 68, 149, 180, 35, 113, 207, 118, 111, 91, 38, 247, 214, 7, 212, 209, 189, 241, 18, 115, 173, 25, 236, 121, 249, 75, 57, 216, 10, 175, 112, 234, 164, 70, 206, 198, 255, 140, 230, 12, 32, 83, 46, 245, 0, 62, 227, 72, 191, 156, 138, 248, 114, 220, 90, 84, 170, 128, 19, 24, 122, 146, 80, 39, 37, 8, 34, 22, 11, 93, 130, 63, 154, 244, 160, 144, 79, 23, 133, 92, 54, 102, 210, 65, 67, 27, 196, 201, 106, 143, 52, 74, 100, 217, 179, 48, 233, 126, 117, 184, 226, 85, 171, 167, 86, 2, 147, 17, 135, 228, 252, 105, 30, 192, 129, 178, 120, 36, 145, 51, 163, 77, 205, 73, 4, 188, 125, 232, 33, 243, 109, 224, 104, 208, 221, 59, 9]
FF1 = [204, 53, 135, 197, 39, 73, 58, 160, 79, 24, 12, 83, 180, 250, 101, 60, 206, 30, 10, 227, 36, 95, 161, 16, 135, 150, 235, 116, 242, 116, 165, 171]
# 两个秘钥
# 定义 a 函数
def a(e, t, r):
n = min(len(e) - t, len(r))
for o in range(n):
e[o + t] = e[o + t] ^ r[o]
return e
# 定义 b 函数
def decrypt(e):
print(e.replace("_", "/").replace("-", "+"))
t = base64.b64decode(e.replace("_", "/").replace("-", "+"))
if len(t) < 16:
return e
r = array.array('B', t[:-16]) # 创建新的字节数组,只包含除最后16个字节之外的部分
u = array.array('B', t[-16:]) # 创建新的字节数组,只包含最后16个字节
for s in range(len(r)):
r[s] = DD1[r[s]] # DD1需要预先定义为一个对应的值映射
for l in range(0, len(r), 16):
r = a(r, l, u) # 对字节数组进行异或操作
for f in range(0, len(r), 32):
r = a(r, f, FF1) # FF1也需要预先定义为一个对应的值映射
return r.tobytes().decode() # 将结果转回字符串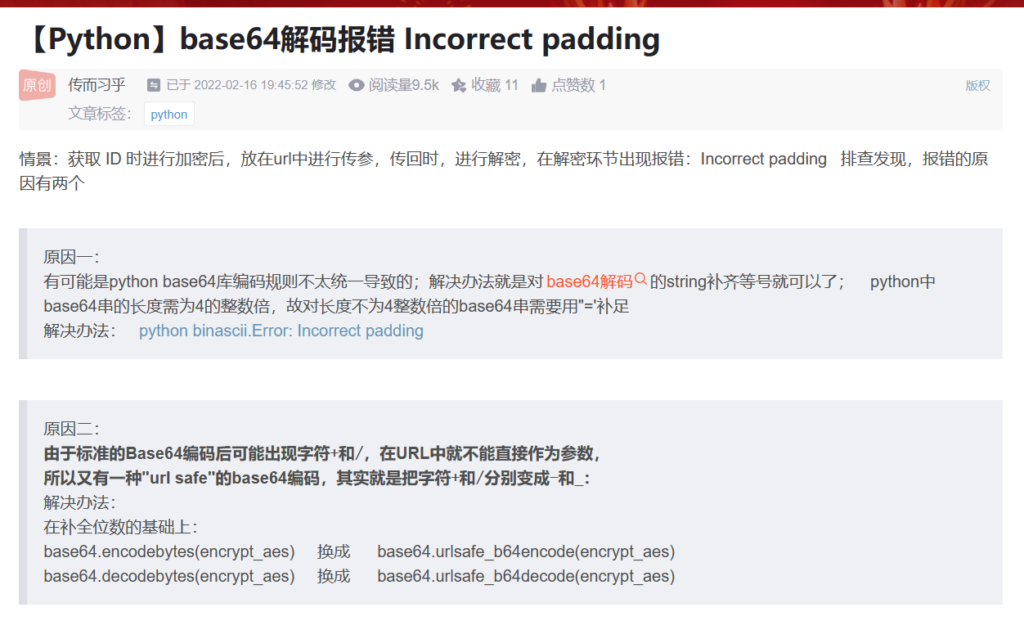
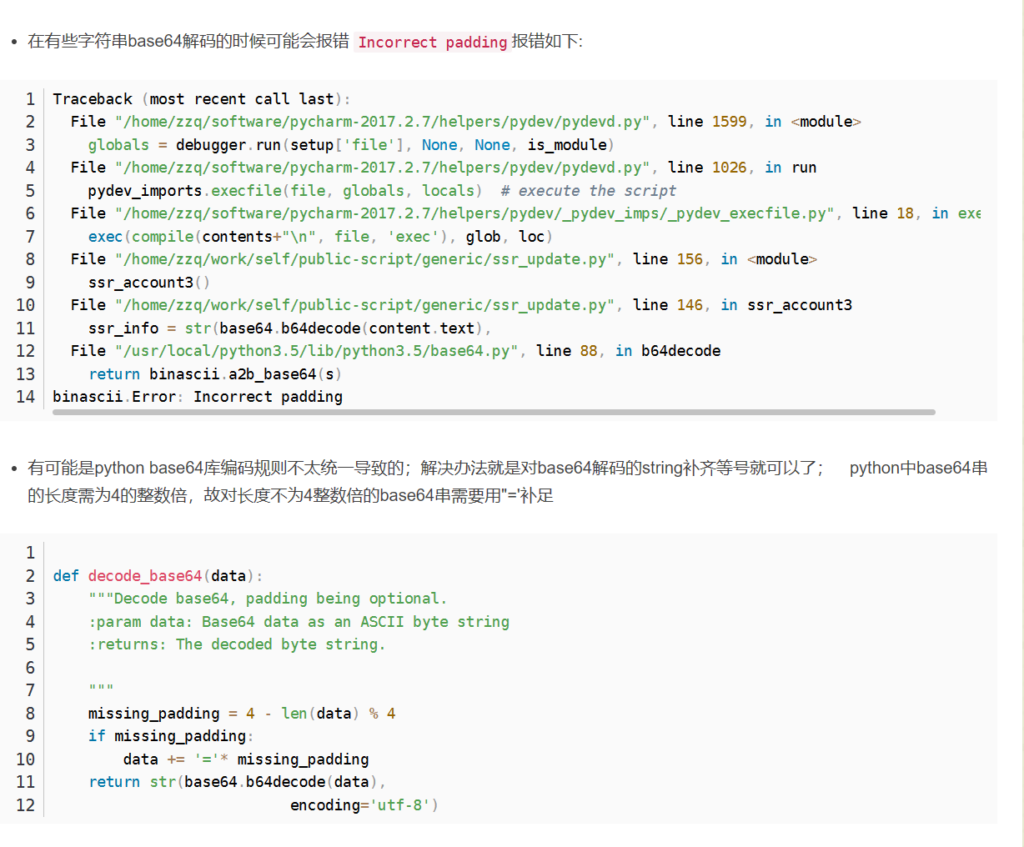
原来这叫urlsafe encode
完整代码
import requests,json,os,time,base64,array,time
"""
23.9.24 下载策略更新&跳过策略&新建文件夹
24.1.23 专辑数据保存,文件名称修复,链接居然加密整死人了,qtmd
"""
TRACK_LIST_URL = 'https://www.ximalaya.com/revision/album/v1/getTracksList'
AUDIO_URL = 'https://www.ximalaya.com/revision/play/v1/audio'
AUDIO_URL_V2 = 'https://www.ximalaya.com/mobile-playpage/track/v3/baseInfo/'
COOKIE = r''
DD1 = [183, 174, 108, 16, 131, 159, 250, 5, 239, 110, 193, 202, 153, 137, 251, 176, 119, 150, 47, 204, 97, 237, 1, 71, 177, 42, 88, 218, 166, 82, 87, 94, 14, 195, 69, 127, 215, 240, 225, 197, 238, 142, 123, 44, 219, 50, 190, 29, 181, 186, 169, 98, 139, 185, 152, 13, 141, 76, 6, 157, 200, 132, 182, 49, 20, 116, 136, 43, 155, 194, 101, 231, 162, 242, 151, 213, 53, 60, 26, 134, 211, 56, 28, 223, 107, 161, 199, 15, 229, 61, 96, 41, 66, 158, 254, 21, 165, 253, 103, 89, 3, 168, 40, 246, 81, 95, 58, 31, 172, 78, 99, 45, 148, 187, 222, 124, 55, 203, 235, 64, 68, 149, 180, 35, 113, 207, 118, 111, 91, 38, 247, 214, 7, 212, 209, 189, 241, 18, 115, 173, 25, 236, 121, 249, 75, 57, 216, 10, 175, 112, 234, 164, 70, 206, 198, 255, 140, 230, 12, 32, 83, 46, 245, 0, 62, 227, 72, 191, 156, 138, 248, 114, 220, 90, 84, 170, 128, 19, 24, 122, 146, 80, 39, 37, 8, 34, 22, 11, 93, 130, 63, 154, 244, 160, 144, 79, 23, 133, 92, 54, 102, 210, 65, 67, 27, 196, 201, 106, 143, 52, 74, 100, 217, 179, 48, 233, 126, 117, 184, 226, 85, 171, 167, 86, 2, 147, 17, 135, 228, 252, 105, 30, 192, 129, 178, 120, 36, 145, 51, 163, 77, 205, 73, 4, 188, 125, 232, 33, 243, 109, 224, 104, 208, 221, 59, 9]
FF1 = [204, 53, 135, 197, 39, 73, 58, 160, 79, 24, 12, 83, 180, 250, 101, 60, 206, 30, 10, 227, 36, 95, 161, 16, 135, 150, 235, 116, 242, 116, 165, 171]
# 两个秘钥
# 定义 a 函数
def a(e, t, r):
n = min(len(e) - t, len(r))
for o in range(n):
e[o + t] = e[o + t] ^ r[o]
return e
# 定义 b 函数
def decrypt(e):
#print(e.replace("_", "/").replace("-", "+"))
missing_padding = 4 - len(e) % 4
if missing_padding:
e += '='* missing_padding
t = base64.urlsafe_b64decode(e)
if len(t) < 16:
return e
r = array.array('B', t[:-16]) # 创建新的字节数组,只包含除最后16个字节之外的部分
u = array.array('B', t[-16:]) # 创建新的字节数组,只包含最后16个字节
for s in range(len(r)):
r[s] = DD1[r[s]] # DD1需要预先定义为一个对应的值映射
for l in range(0, len(r), 16):
r = a(r, l, u) # 对字节数组进行异或操作
for f in range(0, len(r), 32):
r = a(r, f, FF1) # FF1也需要预先定义为一个对应的值映射
return r.tobytes().decode() # 将结果转回字符串
def download(URL,NAME):
print(f'开始下载{NAME}...')
if(os.path.exists(NAME+'.mp3')):
print(f"{NAME}已下载,跳过...")
return
with open(NAME+'.mp3','wb+') as f:
f.write(requests.get(URL).content)
print(f'{NAME}下载完成!')
def namerepair(name:str) -> str: # 文件名规范
name = name.replace('/',' ')
name = name.replace('/\/',' ')
name = name.replace(':',' ')
name = name.replace('*',' ')
name = name.replace('?',' ')
name = name.replace('"',' ')
name = name.replace('<',' ')
name = name.replace('>',' ')
name = name.replace('|',' ')
return name
class album:
tracks:list = []
albumId:str = ''
name:str = ''
totalTracks:int = 0
def saveData(self) -> bool:
with open(f"{self.albumId}.albumdata",'w+',encoding='utf-8') as f:
selfData = {
'name':self.name,
'tracks':self.tracks,
'totalTracks':self.totalTracks,
'albumId':self.albumId
}
f.write(json.dumps(selfData))
f.close()
return True
def getTracks(self) -> bool:
header = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.69',
'cookie':COOKIE
}
param = {
'albumId':self.albumId,
'pageNum':1,
'pageSize':30,
'sort':0
}
ret = requests.get(TRACK_LIST_URL,params = param,headers=header)
ret = json.loads(ret.text)
self.name = ret['data']['tracks'][0]['albumTitle']
self.totalTracks = ret['data']['trackTotalCount']
self.tracks:list = ret['data']['tracks']
rest = self.totalTracks - param['pageSize']
pageNo = 1
while(rest >= 0):
print(f'获取专辑详情,第{pageNo}页')
time.sleep(1)
pageNo += 1
param['pageNum'] = pageNo
rest -= param['pageSize']
ret = requests.get(TRACK_LIST_URL,params = param,headers=header)
ret = json.loads(ret.text)
self.tracks.extend(ret['data']['tracks'])
self.saveData()
return True
def downloadAll(self) -> None:
#pool = ThreadPoolExecutor(max_workers=4)
dir = namerepair(self.name)
if(not os.path.exists(dir)):
os.mkdir(dir)
for j in range(len(self.tracks)):
i = self.tracks[j]
tt = namerepair(i['title'])
if(os.path.exists(f'{dir}\\{tt}'+'.mp3')):
print(f'{dir}\\{tt}已下载,跳过...')
continue
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.69',
'Cookie':COOKIE,
'Host': 'www.ximalaya.com'
}
param = {
'trackId':i['trackId'],
'device':'www2',
'trackQualityLevel':1,
}
#print(i['trackId'])
timeUrl = f'{AUDIO_URL_V2}{int(round(time.time() * 1000))}'
ret = requests.get(timeUrl,params = param,headers=header)
#ret = requests.get('https://www.ximalaya.com/mobile-playpage/track/v3/baseInfo/1706016965133?device=www2&trackId=491707341&trackQualityLevel=1',headers=header)
time.sleep(0.5)
au = json.loads(ret.text)
au = au['trackInfo']['playUrlList'][1]['url']
au = decrypt(au)
while 1:
try:
download(au,f'{dir}\\{tt}')
except:
print('下载出错,1s重试')
time.sleep(1)
continue
break
def __init__(self,albumId:str,refresh:bool = False):
self.albumId = albumId
if(os.path.exists(f"{self.albumId}.albumdata") and refresh == False):
with open(f"{self.albumId}.albumdata",encoding='utf-8') as f:
data = f.read()
data = json.loads(data)
self.name = data['name']
self.tracks = data['tracks']
self.totalTracks = data['totalTracks']
self.albumId = data['albumId']
else:
self.getTracks()
print(self.name)
v = album('56206086')
v.downloadAll()侵删 ch939367561#hotmail.com(#->@)